Quick, find the extra comma!
CSV feels like the simplest of file formats, where it might seem that there’s not much to know after mentally expanding the acronym - Comma Separated Values. But tell me this: if it’s so simple, then why are there so many CSV parsing libraries, alternative CSV parsing libraries, and CSV parsing libraries that claim to be better or smarter, and a mountain of mangled CSVs in existence?
CSV isn’t so much a file format as it is a loose set of guidelines for converting tabular data into text. The closest thing to a spec for it is this, which deals with vital and often overlooked questions such as:
-
“What happens if a value has a comma in it?” - oh, you quote it
-
“What happens if a value has a quote in it?” - oh, you put another quote before it
One question the spec definitely does not cover is one I needed answering: “What do you do with 32,000 files claiming to be valid CSVs but of the 750,000 some lines an unknown number of them have extra unquoted commas hidden in the values, basically making the data untrustworthy?” This is not such a simple problem, but it’s an interesting problem.
Background
I’ve been building a platform for public and community radio stations the last year and have been working with the fantastic 91.7 KOOP in Austin, TX to pilot it. Part of this project involved exporting the data from their old system (some 750,000 tracks) into the system I built for them. And noticing some tracks from an artist named “10” doing a song called “000 maniacs”, I realized the old system’s crusty CSV exporter did not do the right thing when it came to commas in values, leaving me with a real mess.
How many track titles, artists, albums, or record labels have commas in their names? Many.
I initially thought this was an impossible problem to solve (at least in a way that would not drive a person insane) so I tried reaching out to the developer of the old system to fix their ancient CSV exporter, or to send me data in another format that I could sort through myself. This felt like the most straightforward option and didn’t seem like too much of a lift. But after weeks and weeks of back and forth, this path dead ended leaving me with no other option but to fix it myself.
The Problem
Here’s an abbreviated and simplified example of a messed up CSV I was dealing with:
| artist | title | album | label |
|---|---|---|---|
| Lester Sterling | Lynn Taitt & The Jets | Check Point Charlie | Merritone Rock Steady 3: Bang Bang Rock Steady 1966-1968 |
| Lester Sterling | Lester Sterling Special | Merritone Rock Steady 2: This Music Got Soul 1966-1967 | Dub Store |
The way a CSV parser would parse that data currently is like this:
| artist | title | album | label |
|---|---|---|---|
| Lester Sterling | Lynn Taitt & The Jets | Check Point Charlie | Merritone Rock Steady 3: Bang Bang Rock Steady 1966-1968 |
| Lester Sterling | Lester Sterling Special | Merritone Rock Steady 2: This Music Got Soul 1966-1967 | Dub Store |
This is incorrect, and would only be parsed correctly if the artist value were properly quoted, like so:
1
2
3
artist,title,album,label
"Lester Sterling, Lynn Taitt & The Jets",Check Point Charlie,Merritone Rock Steady 3: Bang Bang Rock Steady 1966–1968,Dub Store,
Lester Sterling,Lester Sterling Special,Merritone Rock Steady 2: This Music Got Soul 1966–1967,Dub Store,
Which would be parsed like this:
| artist | title | album | label |
|---|---|---|---|
| Lester Sterling, Lynn Taitt & The Jets | Check Point Charlie | Merritone Rock Steady 3: Bang Bang Rock Steady 1966-1968 | Dub Store |
| Lester Sterling | Lester Sterling Special | Merritone Rock Steady 2: This Music Got Soul 1966-1967 | Dub Store |
But how do we get there without manually looking at 750,000 lines of comma separated text?
Computers, man
First, we can determine if a line is incorrect by parsing it individually as a CSV, seeing how many values we end up with, and comparing that number with the number of headers.
1
2
3
4
5
6
lines = File.read('/path/to/file.csv').lines
header = CSV.parse(lines[0], liberal_parsing: true)
incorrect_lines = lines[1..-1].select do |line|
CSV.parse(line, liberal_parsing: true).values.size != header.values.size
end
1
2
3
4
5
6
7
8
9
10
11
12
[
[
"artist", "title", "album", "label"
],
[
"Lester Sterling", " Lynn Taitt & The Jets", "Check Point Charlie", "Merritone Rock Steady 3: Bang Bang Rock Steady 1966-1968" , "Dub Store"
],
[
"Lester Sterling", "Lester Sterling Special", "Merritone Rock Steady 2: This Music Got Soul 1966-1967", "Dub Store"
]
]
For this example, the header row has 4 values, the first line has 5 values, and the second line has 4 values. The first line is incorrect, meaning there’s an extra comma that belongs within a value.
Knowing that, we need to figure out all the different possibilities of what it could be. One of those possibilities will be the correct one, and the rest will be wrong. With five values and four fields, we need to join two values together into one (and quote it), making four values.
I think best on paper, so I started drawing out how this might work in a brute force sort of way, to try to get a handle on the algorithm I needed.
Eliminate 1 position, Fit 5 into 4
[1, 2, 3, 4, 5] -> [x, x, x, x] =>
[[1, 2], 3, 4, 5]
[1, [2, 3], 4, 5]
[1, 2, [3, 4], 5]
[1, 2, 3, [4, 5]]
What if we had two commas in there? Then we’d have six values needing to fit into four slots.
Eliminate 2 positions, Fit 6 into 4
[1, 2, 3, 4, 5, 6] -> [x, x, x, x] =>
[[1, 2, 3], 4, 5, 6]
[1, [2, 3, 4], 5, 6]
[1, 2, [3, 4, 5], 6]
[1, 2, 3, [4, 5, 6]]
[[1, 2], [3, 4], 5, 6]
[[1, 2], 3, [4, 5], 6]
[[1, 2], 3, 4, [5, 6]]
[1, [2, 3], [4, 5], 6]
[1, [2, 3], 4, [5, 6]]
[1, 2, [3, 4], [5, 6]]
This was pretty easy to visualize and draw out on paper manually, but figuring out how to do this programmatically for any situation was a challenge. This sort of combination/permutation type math felt like the type of thing I would have learned in a Probability and Statistics class that I took in college, but you know what I remember from that class?
- Having a huge crush on a lil’ cutie and zero game to do anything about it
- Drawing this funny comic
This was less dark in 2002
That’s what I remember. Certainly not this practical math.
The Actual Question
Anyway, turns out the question we’re trying to answer is: if v is the number of values we have (5), and h is the number of headers we have (4), what are all the unique permutations of h numbers that add up to v?
The following looks similar to the written out paper breakdowns from before, but now instead of each number representing a position, each number represents how many values will be joined together.
What are all the permutations of 4 numbers that add up to 5?
[2, 1, 1, 1] # join the first two values together
[1, 2, 1, 1] # join the second and third values together
[1, 1, 2, 1] # join the third and fourth values together
[1, 1, 1, 2] # join the fourth and fifth values together
To calculate this programmatically, we can first calculate the unique combinations using the method below that I nicked from a stack overflow post that has since been lost in my browser history. There were a number of them, and this one seemed most performant.
1
2
3
4
5
6
7
8
9
10
11
12
13
def combos(desired_size, count, minimum = 1)
# determine all combinations of [count] numbers that add up to [desired_size]
# e.g if we have an array of 6 items and want an array of 4 items
# we need 4 numbers that add up to 6, => [[1, 1, 1, 3], [1, 1, 2, 2]]
return [] if desired_size < count || desired_size < minimum
return [desired_size] if count == 1
(minimum..desired_size - 1).flat_map do |i|
combos(desired_size - i, count - 1, i).map { |r| [i, *r] }
end
end
Given these combinations we can now calculate all the different permutations of those sets, which is basically just getting every ordering of those numbers and then eliminating duplicates.
Here’s a class that does all this:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
module CommaSplice
class JoinCalculator
attr_reader :from_size, :to_size
def initialize(value_count, header_count)
@from_size = value_count
@to_size = header_count
end
def possibilities
@possibilities ||= permutations(combos(from_size, to_size))
end
private
def permutations(combinations)
# get all permutations of those combinations
# to determine every possibility of join
all_permutations = combinations.collect do |combo|
combo.permutation(to_size).to_a
end
# flatten down to a list of arrays
all_permutations.flatten(1).uniq
end
def combos(desired_size, count, minimum = 1)
# determine all combinations of [count] numbers that add up to [desired_size]
# e.g if we have an array of 6 items and want an array of 4 items
# we need 4 numbers that add up to 6, => [[1, 1, 1, 3], [1, 1, 2, 2]]
return [] if desired_size < count || desired_size < minimum
return [desired_size] if count == 1
(minimum..desired_size - 1).flat_map do |i|
combos(desired_size - i, count - 1, i).map { |r| [i, *r] }
end
end
end
end
# CommaSplice::JoinCalculator.new(6, 4).possibilities
# #=> [[1,1,1,2], [1,1,2,1], [1,2,1,1], [2,1,1,1]]`
Now given all the permutation options, we can loop through them and generate all the value possibilities.
1
2
3
4
5
6
7
8
9
10
11
join_possibilities.collect do |joins|
values = @values.dup
joins.collect do |join_num|
v = values.shift(join_num)
if v.size > 1
quote_values(v)
else
v.first
end
end
end
Here are the value possibilities. Five values made into four.
At this point, we could match these up with the headers and prompt the user with the option, making the task a little less tedious, like so:
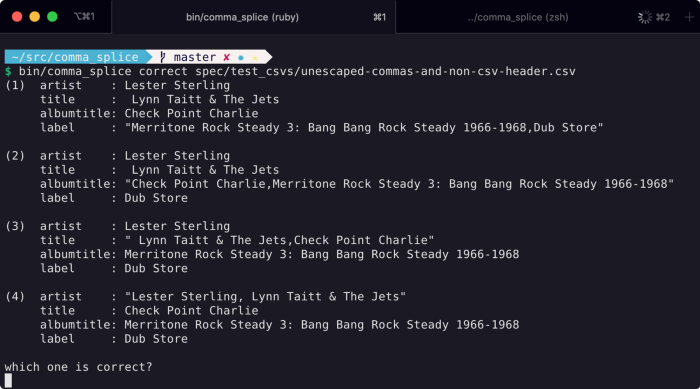
And that’s a pretty good worst case scenario! But there’s still something we can do to determine which one of these is most likely correct without dying from boredom after doing this thousands of times.
The Human Element
You might have already have caught this, and if so — nice work, you’re sharp — but this crucial fact only hit me when I was a mile deep into this problem: when people type commas out they generally put a space after it. So if a parsed value starts with a space…it’s probably not the correct choice.
So in this example we can obviously see that option number 4 is the correct one, since every other one has a value starting with a space. So most of the time, we can reject any choice where any value starts with a space.
This doesn’t always work! With 750,000 manually entered tracks, you can bet people made typos, and you can bet there are tracks that have commas without spaces after them, like this beauty:
Deftones,U,U,D,D,L,R,L,R,Select,Start,Saturday Night Wrist,Maverick
(which, by the way, generates 220 possible options with no great way to determine which one is correct without a human and/or an internet connection. Oy vey.)
But this method works well enough to turn what I initially thought to be an impossible task into a very very doable task, which I’m happy to report I completed successfully.
I packaged all this code into a ruby gem (with a command line option) on the off chance that some other poor soul has found themselves in a similar CSV parsing dilemma. If that’s you: the chances of you getting out of that situation alive? Better than average.